

Knowing the different techniques for scaling databases, help us to choose the appropriate strategy to adapt to our needs and purpose.
Hence, in this post, we will demonstrate different solutions and techniques for scaling databases server. They are divided between reading and writing strategies.
Reading/Loading
Sometimes we have applications that are under so much load. And to deal with this issue, we demonstrate three different techniques that we can implement.
Databases scaling – Caching
Caching technique stores frequently requested data or expensive computing operations responses in temporary memory. The data stored in the cache needs to be changed by the nature of the application, and to update them, the cache invalidation and eviction technique can be used to maintain the consistency of the data. It can be achieved with the cache expired time to live (TTL) method or others dependent on the caching patterns used.
Different caching patterns can be used as a strategy to implement caching solutions. Caching aside supports heavy reads and works even if the cache goes down. Read-through and Write-through are used together. They are great alternatives for read-heavy workloads but cache failure results in system failure. Write-back is useful for writing heavy workloads, and it is used by various DBMS implementations.

Depending on the requirements such as heavy reading or heavy writing or a mix of both, we can decide which pattern to use in a way that we can afford cache or database failure.
Databases scaling – Replication
Replication works with having one database referred to as main where all the writing request flow to it. In addition, we make an exact copy of that main database as new node replicas known as secondary, responsible only for dealing with the reading requests. The main database constantly feeds the slaves nodes with more recent data keeping our information consistent between all the nodes in the cluster.
Replication is a great strategy to deal with fault tolerance and maintain the CAP theorem and system scalability. Suppose one of the nodes go1es down, we continue to serve as we have the same data replicated in the other nodes. Also in a cluster, a node can take over and become a main database in case of primary node failure. Replication also helps reduce latency in the application, once we can have our database deployed and data replicated on different regions such as CDN and it can be accessed easily by the local users.

Synchronous and asynchronous
Besides those advantages, maintaining consistency in the replica node, became complicated with the increase of the nodes. This problem can be solved using a synchronous or asynchronous replication strategy depending on the requirements.
The synchronous strategy has the advantage of the lag being zero, and the data is always consistent, but as a downside, the performance is affected once it is necessary to wait till all the replicas are updated and acknowledged by the issuer. On the other hand, in the asynchronous strategy, the writes became faster as the main node does not wait for the acknowledgment, but rise the problem of an inconsistent state if a replica fails to update the value.
Bear in mind that there is no silver bullet, the best strategy depends on our needs. A trade-off must be assumed between consistency, availability, or partition (CAP Theorem). The CAP theorem state that we can guarantee only two of them at a time.
Databases scaling – Indexing
Indexing is used to locate and quickly access data, improving the performance of database activity. A database table can have one or more indexes associated with it.
Indexing improves query performance with faster data retrieval, it enhances data access efficiency, decreasing the number of I/O for retrieving the data. It optimizes data sorting since the database does not need to sort the entire table and instead only the relevant rows. Indexing maintains the data consistent even with the rise in the amount of data. Also, indexing ensures database integrity, avoiding storing duplicated data.
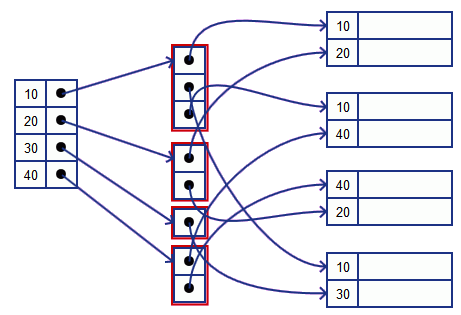
As a drawback, indexing needs more storage which increases the database size. It also increases the maintenance overhead with addition, removal, and modifications in the table. Indexing can reduce performance in insert and update. Choosing an index can be difficult for a specific query or application.
Writing
For applications that have a lot of writing to the database with the users constantly harming it with new data, we have sharding and NoSQL as strategies.
Databases scaling – Sharding
Sharding or data partition allows the separation of large databases data into smaller, faster, more easily managed parts, splitting the database into multiple main databases. There are two kinds of sharding, vertical and horizontal.
The data partition has the advantage of query optimization bringing a better performance and reducing latency. It allows the possibility to have users’ data across different locations that can be accessed faster for users in particular regions. Also, it has the advantage of avoiding a single point o failure.
One of the drawbacks of sharding is partition overloaded in case we did not distribute the data across the partition correctly. Depending on the strategy we choose, we can end up with some partitions with a lot of data and some with fewer data, and the query on that large partition can become slower. Another disadvantage is to come back and recover the prior state of the no-sharding strategy once it was implemented and the data split across different databases.
The application of partition can be logical or physical. A logical sharding is when we have a different subset of the data in the same physical machine, and a physical sharding can have more than one subset of partitions in a physical machine.
For partitioning the data, we can choose between algorithm sharding or dynamic sharding. There exist different algorithms and dynamic sharding technics since key-based, range-based, and directory-based sharding as the most used.
Vertical sharding
For vertical sharding, we take each table and put them on a different machine. Such as user tables, log tables, or comment tables, each on different machines. Vertical sharding is effective when queries tend to return only a subset of columns of the data. For example, if some queries request only names, and others request only addresses, then the names and addresses can be sharded onto separate servers.

Horizontal sharding
In case we have a single table that is became very large, we apply horizontal sharding. We take a single table and split a chunk of related data across multiple machines. Horizontal sharding is effective when queries tend to return a subset of rows that are often grouped. For example, queries that filter data based on short date ranges are ideal for horizontal sharding, since the date range will necessarily limit querying to only a subset of the servers.

Databases scaling – No SQL
No SQl is not a relational database and essentially is a key-value pair. A key-value pair models are naturally able to scale easily by themselves across multiple different machines. NoSQL is classified into four main categories, Column-oriented which stores data as column families, Graph stores data as nodes and edges, Key-Value stores data as key-value pairs and Document stores data as semi-structured documents.

It allows dynamic schema which can accommodate changes without schema alterations. Also, it provides horizontal scalability since it was designed to scale out by adding more nodes to a database cluster. It is also designed for high availability to handle node failures automatically and data replication across multiple nodes in the cluster.
This no-relational database offers several benefits over relational databases, such as scalability, flexibility, and cost-effectiveness. However, they also have several drawbacks, such as a lack of standardization, lack of ACID compliance, and lack of support for complex queries.
Conclusion
In this article, we demonstrated strategies to be implemented when dealing with database scalability.
We split it between reading and writing strategies. For reading, we can apply different caching mechanisms, replication with primary and secondary databases as well as implement indexing to locate and quickly access the data. For writing scalability there are sharding or NoSQl strategies, both with their advantages and drawback.
Finally, bear in mind that there are no perfect solutions, we need to understand our requirements and apply trade-offs to choose the best strategies for our application.